
The First AI Model That IS the Chip: 17,000 Tokens Per Second. No Memory. No GPU!
A 25-person team baked Llama 8B directly into a chip and hit 17,000 tokens per second. That's up to 28x faster than Cerebras, Groq, and Nvidia.


For years we’ve been running language models the same way: you take a GPU, you load weights into memory, you push tokens through. The bottleneck was always the memory wall, that constant shuffle between where the model lives and where computation happens.

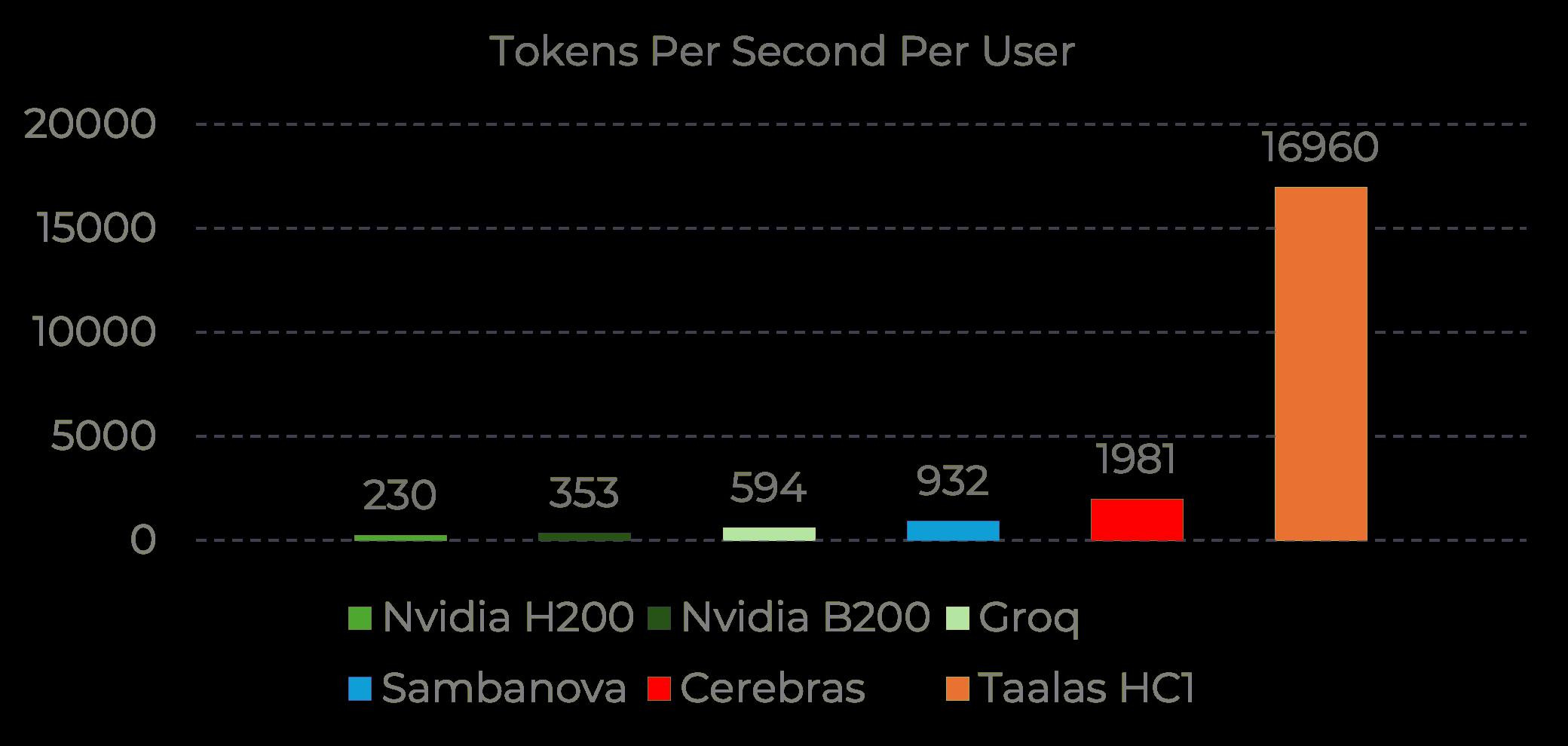
Taalas, a 25-person team mostly out of Tenstorrent, decided to skip that problem entirely. They took Llama 3.1 8B and literally baked its weights into the transistors of a custom chip. There is no separate memory. The model and the silicon are the same thing. Their first chip, HC1, runs on TSMC 6nm with 53 billion transistors, draws about 200 watts per card, and pushes 17,000 tokens per second on Llama 8B. For context, Cerebras does around 2,000 on the same model, Groq sits at 600, and a single Nvidia B200 delivers roughly 3.5x less throughput at comparable power. You can actually try it yourself at chatjimmy.ai, and the speed is honestly startling when you see it in real time.
0.058s per 15,747 tockent. You blink SLOWER!
The obvious question is: if the model is frozen into the chip, what happens when a better model comes out? You can’t flash new weights onto this thing. That’s a real constraint, and Taalas doesn’t pretend otherwise. But the economics change the calculation. Printing a new version of the chip through TSMC takes about two months and costs roughly 1% of what training the model cost in the first place. On top of that, they kept support for LoRA adapters and variable context windows, so you can still fine-tune and adjust behavior without touching the base weights. It’s not as flexible as a GPU, but it’s far from a dead end.
Where this gets interesting is what it means for the people who actually pay inference bills. If you’re an API provider serving millions of requests, swapping a rack of B200s for a box of these cards could cut your costs by an order of magnitude. If you’re building voice agents or real-time applications where every millisecond of latency matters, single-digit response times without batching change what’s possible. And for entire regions where Nvidia hardware is priced out of reach, a chip that costs 20 times less to produce suddenly opens a door that was locked. Taalas says they’ll have a 20B reasoning model on HC1 by summer and a frontier-class model on second-generation silicon by winter. I keep thinking about the moment this approach hits the 70B+ range. That’s when things get really wild.
Interesting but over optimistic IMHO. 8x transistors for dataset set a limit for what can be implemented. 2-months cycle of production for TSMC - it’s actually their minimum for now, I mean really minimal production time right now for ANY price. But the idea is good, question is in outsourcing weights to some kind of ram, mean same architecture but on physical level weights are in ram . Or they have analogue design? It’ll be super trick)) And what scares me- it is a first disposable LLM.