
The Perplexity Dilemma: Lessons of The Middleware King
I studied a Perplexity's strategic positioning this week. Dive my analysis on the AI industry in months. And rethink your own stack with me.


On February 25th, Perplexity shipped Computer. Not a laptop. A cloud-native multi-model orchestration system that routes work across 19 frontier models. It spawns sub-agents. It persists memory for months. It delivers finished artifacts while you sleep. It runs Claude Opus 4.6 as its reasoning core, Gemini for deep research, Grok for speed, GPT-5.2 for long context recall. $200/month. And by most accounts, it’s genuinely impressive for research, competitive intelligence, and consulting-grade deliverables.
And it might not matter.
The middleware trap, explained simply
Within six weeks of Computer’s launch, three things happened simultaneously. Anthropic shipped the enterprise expansion of Claude Co-work with deep connectors and private plug-in marketplaces. Google shipped Gemini agents at the OS level on Android. OpenAI started embedding forward-deployed engineers directly inside enterprise customers to set up Frontier.
Three different architectures. Three hyperscalers. All building the exact product Perplexity Computer competes with.
And here’s the problem I can’t stop thinking about: every model provider Perplexity depends on is simultaneously building the thing Computer is. The reasoning engine is Anthropic’s. The research layer is Google’s. The speed layer is xAI’s. The long-context layer is OpenAI’s. Perplexity is running a product where every component of the supply chain is also a direct competitor.
That is the middleware trap.
Why this matters to every creator and founder who doesn’t own a model
If you’re building on top of someone else’s language model, someone else’s API, someone else’s platform, you are in the same structural position as Perplexity. Just smaller and with less capital to burn.
I’ve been building agentic marketing systems for 9 months. Every pipeline I run depends on Claude’s API. Every deployment touches infrastructure I don’t control. If Anthropic decides tomorrow that my use case is worth absorbing, they don’t need to beat me. They just need to be good enough. And they already are.
This is not hypothetical. This is what Microsoft did to Netscape. What Amazon did to early AWS competitors. What Google did with Analytics. The playbook is old. The speed is new.
It called “the middleware squeeze.” The layers below you are controlled by hyperscalers who need downstream tokens to justify their valuations. The layers above you are the customer relationships. You’re in between. And “in between” is the worst place to be when the companies below you and above you start reaching toward each other.
The stack, as it stands right now
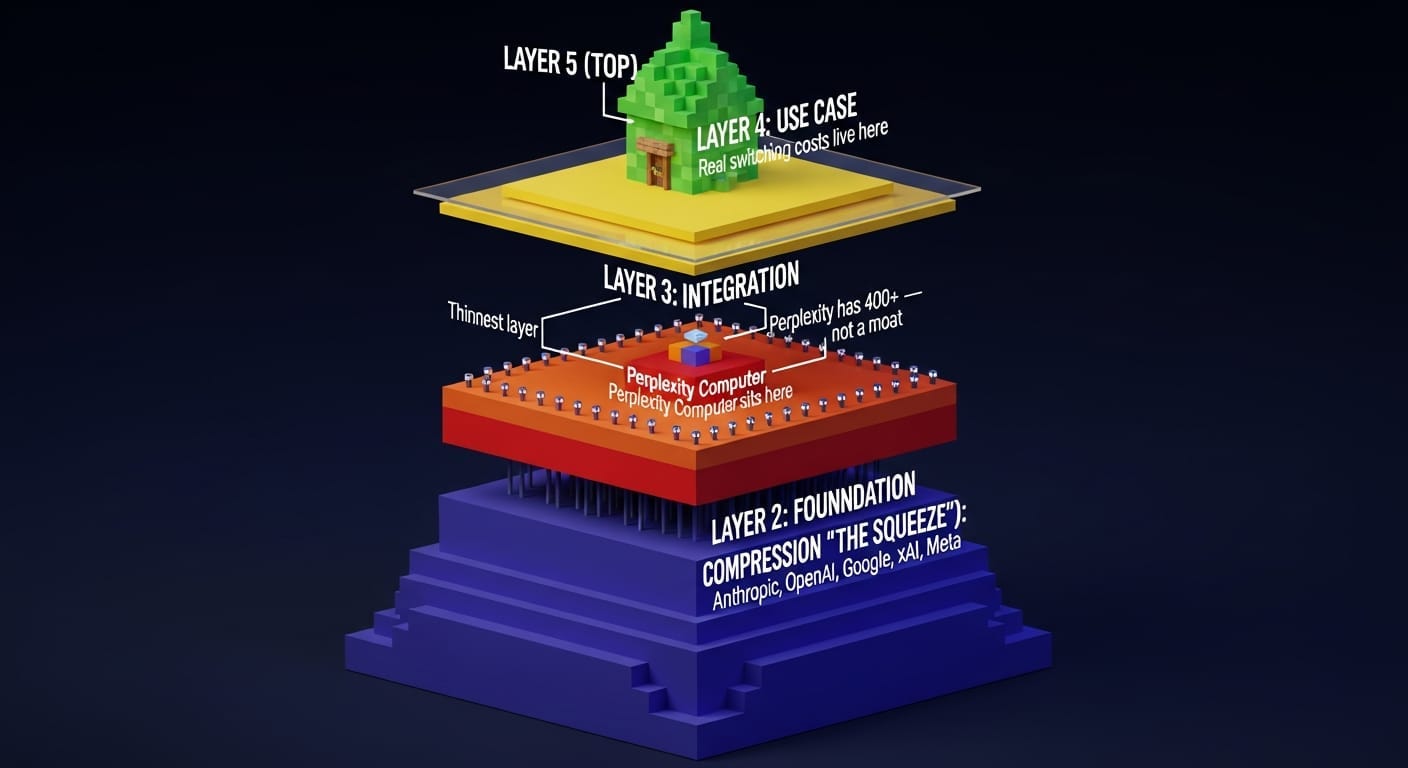
I broke down the AI industry into five layers:
Layer 1 — Foundation. Models and compute. Owned by Anthropic, OpenAI, Google, xAI, Meta. You and I don’t play here.
Layer 2 — Orchestration. Multi-agent frameworks, context management, task routing. This is where Perplexity Computer sits. This is also where every agentic startup sits that doesn’t own a model.
Layer 3 — Integration. Tool connectors, API bridges, workflow triggers. Perplexity has 400+. Sounds like a moat. Isn’t one. Every integration is a contract with a company that has its own interests and can cut you off.
Layer 4 — Interface. Chatbots, voice, IDEs, custom UIs. This is where most “AI startups” live. It’s the thinnest layer.
Layer 5 — Use case. Domain-specific agents, industry workflows. This is where real switching costs live, if you build them right.
The squeeze happens in layers 2-4. The hyperscalers own layer 1 and are reaching up. Enterprise customers own layer 5 and are reaching down. Everything in between gets compressed.
Three moats that were supposed to work (and why two of them don’t)
“Domain expertise.” Most of what companies call domain expertise is actually context loading. You’re dropping your use case into a big context window. That’s not a moat. That’s a prompt. Claude Opus 4.6’s million-token context window is specifically designed to sit inside enterprise workflows as an omnipresent context anchor. Your carefully curated knowledge base is one API call away from being someone else’s feature.
The exception: if your domain expertise lives in proprietary data, years of regulatory compliance, or operational insight from running physical processes, you might be safe. For now. But most companies claiming domain moats haven’t done the honest work to figure out which side of that line they’re on.
“Integrations.” Perplexity has 400+ integrations. That sounds defensible until you remember that every one of those is a contract with a company that has its own AI ambitions. Ask anyone who built on Twitter’s API. Ask anyone who relied on LinkedIn’s API before it got shut down. Integration moats get dismantled the moment the platform decides it wants the token.
“Switching costs.” This is the only moat that actually holds. But not the way most people build it. Switching costs don’t come from being embedded. They come from the cost of replacing you being higher than the cost of keeping you. There’s a difference. Embedding deeply is necessary but not sufficient.
OpenAI parking forward-deployed engineers inside enterprise customers is specifically designed to build this kind of switching cost. They’re not selling API access. They’re building structural relationships that make switching expensive. If you’re a middleware company, that’s the game you need to play. And if you can’t, you need to know it now.
Seven lessons for creators and founders who don’t own the stack
I pressure-tested them against my own experience building agentic systems over the last 9 months. Some of them hurt.
1. If your product runs on a competitor’s model, you are renting your differentiation. Every model generation that ships a new capability can collapse your entire value proposition overnight. A million-token context window eliminated several categories of multi-model routing that Perplexity depended on. What does the next capability jump eliminate for you?
2. The question is not “is my product good?” The question is “why does the value live here and nowhere else?” If you cannot answer that and defend the answer for more than one model generation, you are generic middleware. Generic middleware gets slowly replaced as model capabilities expand. Not killed overnight. Just compressed until the margin is zero.
3. Good execution on the wrong layer of the stack will not save you. Perplexity Computer is a genuinely impressive product. And it does not solve any of their strategic vulnerabilities. It actually introduces new ones. Execution quality and strategic position are independent variables.
4. Three clocks are running at different speeds, and only one matters. Model providers ship capability jumps in weeks. Enterprise procurement locks in platform decisions for 6-18 months. Hyperscaler capex needs returns in 2-3 years. The clock that matters is the first one. Every capability jump that collapses your differentiation narrows the window for repositioning.
5. Pick your lane or get squeezed. There are exactly three viable positions for companies that don’t own a model: (a) infrastructure — be a building block that agents need regardless of who wins orchestration; (b) vertical app — own a domain so deeply that switching costs are real; (c) enterprise workflow tool — encode institutional knowledge that survives a model update. If you are none of these, you are generic middleware and the compression has already started.
6. Don’t compete for token routing. Whoever controls orchestration controls token routing. Whoever controls token routing controls downstream revenue. Microsoft wants tokens through Azure. AWS wants tokens in their model garden. Google wants tokens in Vertex. Every token that flows through a neutral third party is a customer one of them doesn’t get. That is a zero-sum game. Do not get in the middle of it unless you enjoy being squeezed from three sides simultaneously.
7. The trust and verification gap is the biggest unclaimed opportunity. Agents are doing real work. No one can prove what agents did. The gap between “agents act” and “we can audit what agents did” is wide and growing. This is analogous to what accounting firms did when financial complexity started to outpace regulation. Someone needs to audit agent outputs, verify compliance, and enforce policy. The model providers are focused on capabilities right now. Governance is wide open.
What I’m doing differently after this
Three things changed in my own thinking this week.
First, I stopped assuming that “I built it on Claude” is a feature. It’s a dependency. The pipeline I built works today. It might be a native Claude feature in 6 months. I need to know which parts of my system would survive that, and which wouldn’t.
Second, I started mapping my own stack against the five-layer model. Most of what I do lives in layer 2-3. That’s the squeeze zone. The parts that live in layer 5, the domain-specific workflows that encode my actual marketing operations knowledge, those are the parts worth protecting. Everything else is scaffolding.
Third, I’m paying much more attention to the clock. Not the enterprise procurement clock. Not the capex clock. The capability clock. Every model generation that ships is a pressure test on whether my work is still differentiated or just hasn’t been commoditized yet.
The Perplexity dilemma is not about Perplexity. It’s about everyone who builds on top of someone else’s foundation and calls it a product.
The hyperscalers need downstream tokens. The rest of us need to figure out which of our tokens are truly ours.
Good luck with that. I’ll be here, building.