
What Happens When You Simulate 76 People Arguing About Your Brand's Future for Five Years
24 million tokens. That's what a five-year behavioral simulation of 76 audience segments costs in compute. In real money — using a cost-efficient model — that's about $15. BIG SHIFT!


IMPORTANT: The interface is in Chinese, so all screens you'll see are shown via screen translation.
Today I ran a five-year simulation of a fitness club network operating in Ukraine — under conditions of active war, demographic decline, and accelerating population outflow.
76 virtual people participated. Each had a personality, a memory, a bias, and a stake. They argued, reacted to events, and changed their behavior across simulated quarters. The system tracked how each audience segment — young professionals, families, older members, emigrants who might return — shifted their relationship to the brand over time.
The tool that made this possible: MiroFish. A 20-year-old student built it in 10 days using vibe coding. It has 15,500 GitHub stars. Shanda’s founder Chen Tianqiao committed $30M to it within 24 hours of seeing the demo.

I spent around 24 million tokens running the simulation. That number matters. Let me come back to it.
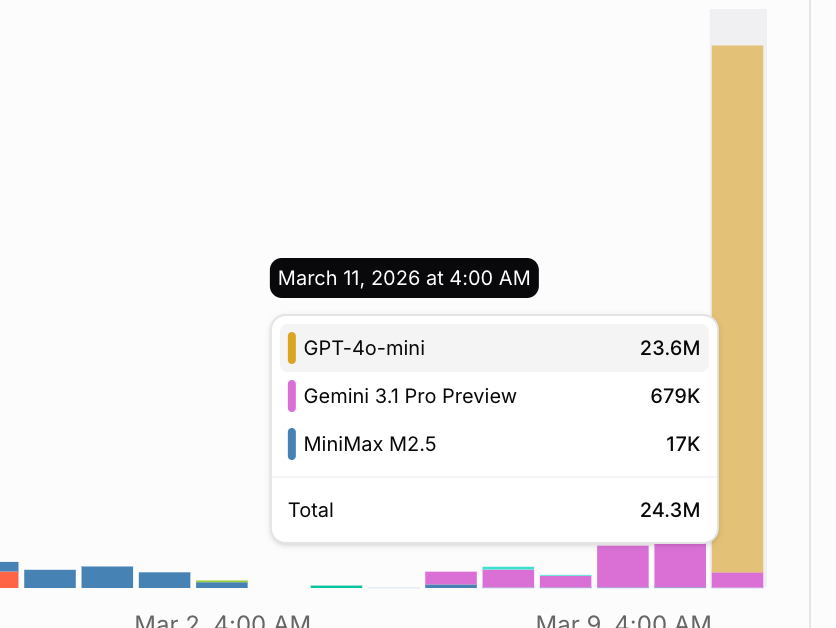
Can you imagine the cost of this research via Opus? :)
What MiroFish Actually Does
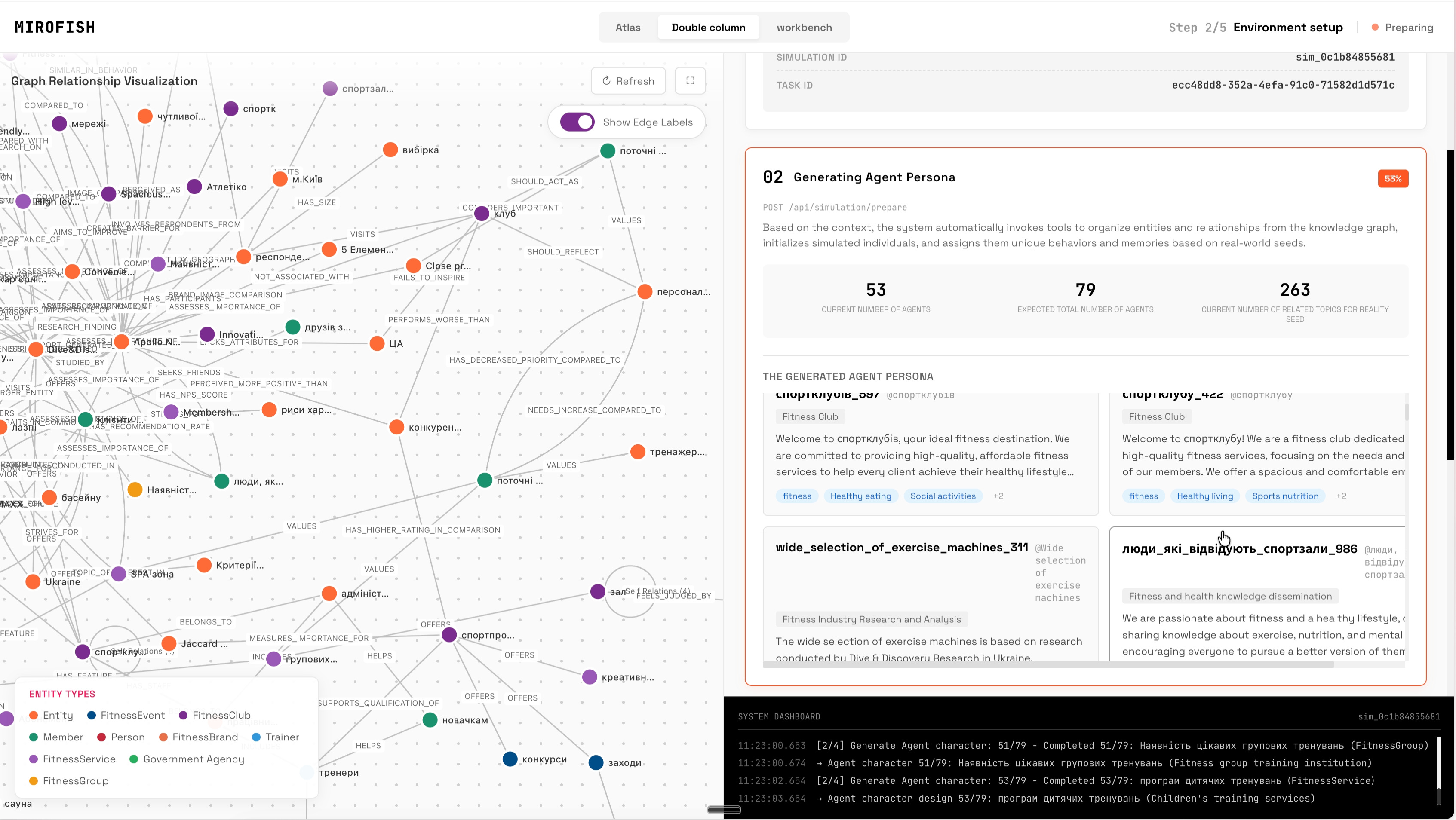
You feed it a document — a brand research report, a market analysis, a news package, anything with structured context. I had a Brand Health Monitor Report done by the external agency with the interviews of 600+ respondents all over the country. The system reads it, builds a knowledge graph of every entity mentioned: people, organizations, audience segments, media outlets, and competitors. Each node in that graph becomes an agent.
Each agent gets a full persona: age, gender, MBTI, professional context, values, communication style, and a bias score toward the topic you’re studying. Then you set the simulation parameters — a five-year horizon broken into quarterly rounds, with events injected at each period (a new wave of emigration, an economic shock, a competitor opening nearby, a ceasefire announcement).
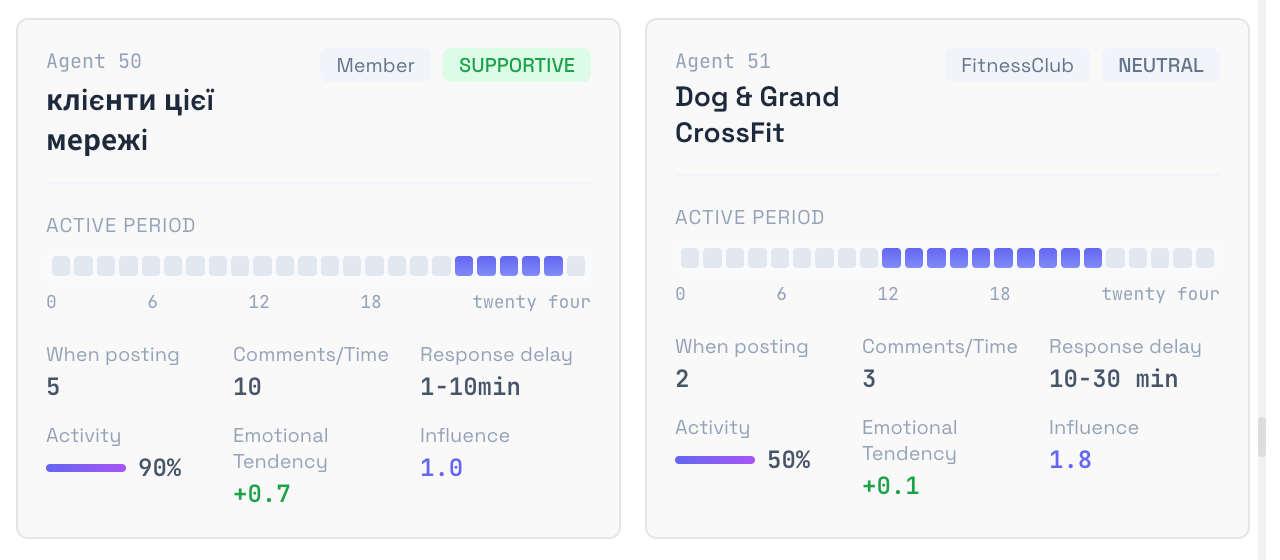
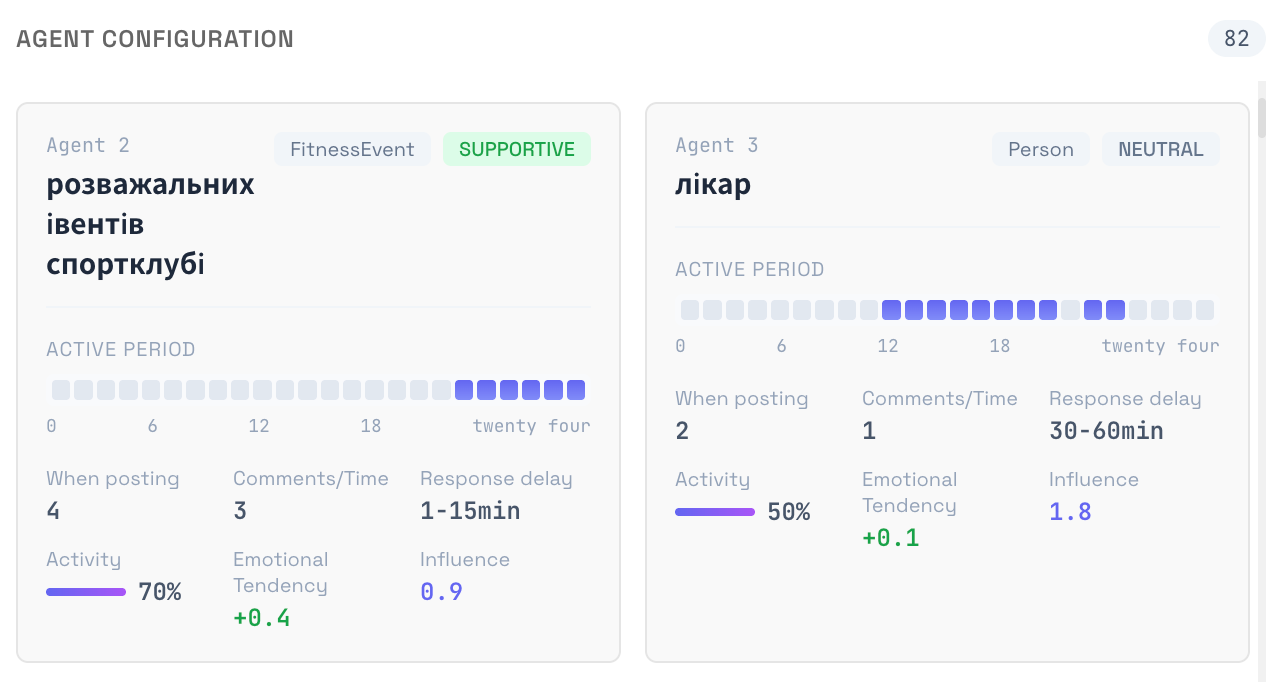
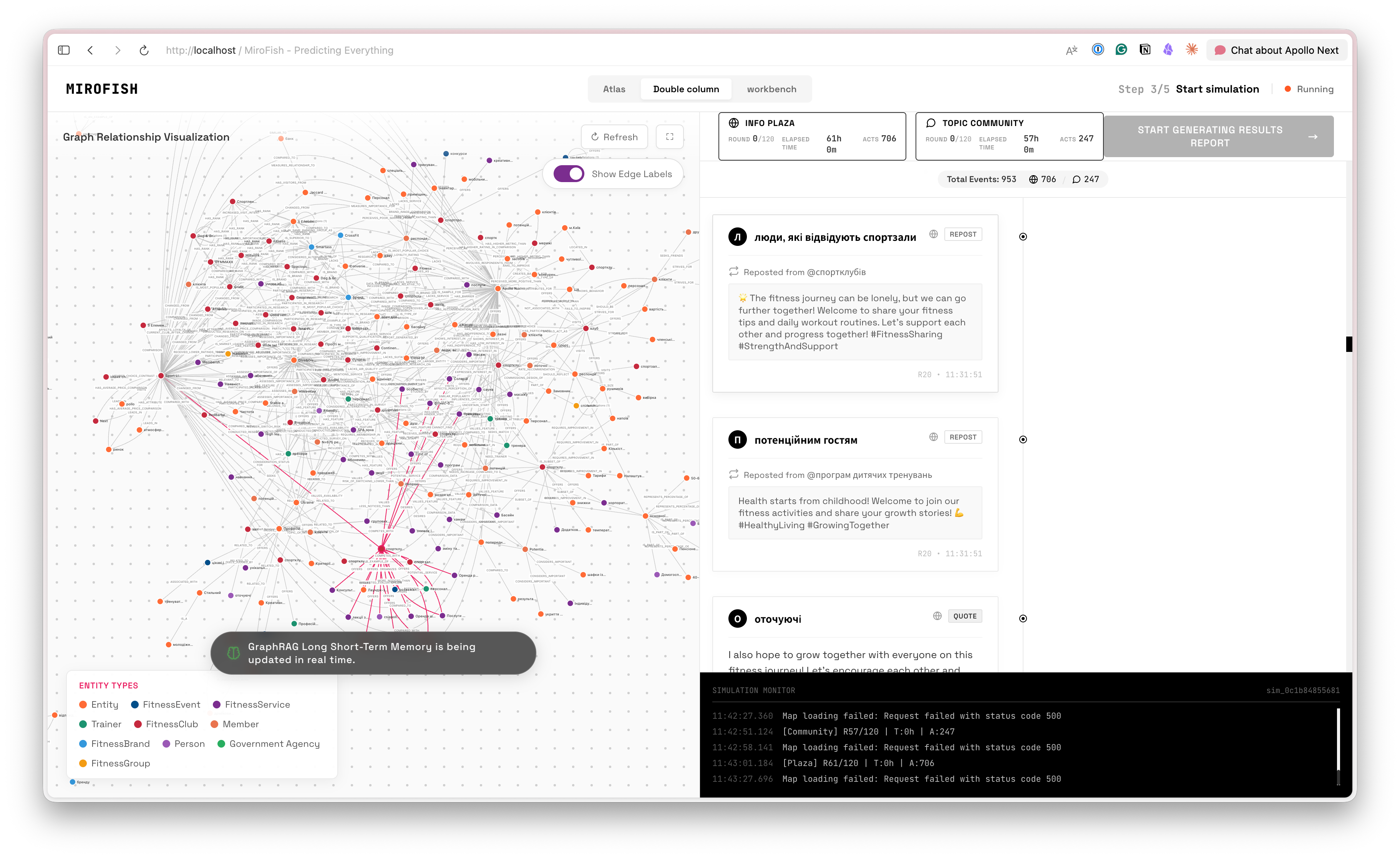
In each round, every agent sees a shared information feed and decides: post, comment, react, or stay silent. The decisions come from their character and their memory of previous rounds. The system records the dynamics — who leads opinion, who goes quiet, which communities form, which segments disengage.
At the end, a Report Agent synthesizes everything into an analytical brief. You can interrogate it.
The Simulation I Ran
The question I asked: How will different audience segments of a Ukrainian fitness brand behave over 5 years given demographic decline, youth emigration, and sustained probability of active conflict?
The system generated 76 agents from a brand research document. That’s 76 synthetic stakeholders — not survey respondents, not hand-crafted personas, but entities extracted directly from real research data and given behavioral autonomy.
Events injected across the simulation horizon:
Continued military operations, periodic escalation
Accelerating demographic shift (-15% active population by year 3)
Economic compression is reducing discretionary spending
Emigrant communities forming abroad with partial brand loyalty
Competitor consolidation in the market
The results were specific in a way that focus groups rarely are. Certain segments showed resilience. Others showed a clean exit trajectory. The model identified which audience clusters would become the core of the business by year five — and which were already gone regardless of what the brand did.
The Number That Puts This in Context
24 million tokens sounds abstract until you compare it to what this analysis would cost done traditionally.
The global market research industry is worth $84.6 billion per year. A McKinsey or BCG strategy engagement covering market trajectory analysis runs $500K–$1.25M and takes 8–12 weeks with a team of 5–15 analysts. A RAND Corporation demographic research contract: $500K–$5M. A custom agent-based simulation model built by an academic team: $50K–$500K and 3–12 months of development.
Traditional consumer survey covering 1,000 respondents: $50,000–$150,000. A 5-year market forecast from a top consulting firm: $150,000–$500,000+.
The 40M tokens I spent on MiroFish using a cost-efficient LLM (MiniMax M2.5 via OpenRouter at $0.27/1M input tokens) cost roughly $8–15. With a less optimized model choice, the same run could reach $300–500. With GPT-4, you’re looking at $1,000–3,000 for the same simulation.
This is a 1,000x–10,000x cost reduction against the traditional benchmark. The time compression is equally dramatic — hours instead of months.
What This Means for the $30 Warning
24 million tokens is a lot. At GPT-4 pricing, that simulation would cost $1,500+. It’s easy to run up a significant bill if you’re not paying attention to model choice.
The technical reality: MiroFish consumes 14,000–18,000 input tokens per agent per round. Multiply by 76 agents and 40 rounds, and the token math compounds quickly. A few specific rules before you start:
Choose your LLM carefully. MiniMax M2.5 ($0.27/1M input) or Qwen-plus ($0.30/1M) are purpose-built for high-volume agent workloads. GPT-4 is 10–15x more expensive for the same task. Run the math before you hit start.
Start small. 20 agents, 15 rounds. That’s a valid test that costs under $3 and tells you whether the simulation is giving you a useful signal.
Scale deliberately. Only scale to 76+ agents when you have a question worth the compute.
Who Should Run This Before Anyone Else
Every CMO doing demand forecasting for a new market entry. Every founder assessing product-market fit in a volatile environment. Every strategist trying to understand how different audience segments will react to a positioning change, a price increase, or a crisis.
This is particularly powerful at business launch. Before you commit to a market, you can simulate how the market responds — not based on gut feel or a 100-person survey, but based on a structured behavioral model of everyone relevant to your success.
The tool is not perfect. LLM agents behave the way the model thinks a persona would behave — not exactly like real humans. Quantitative predictions are unreliable. But for directional intelligence — understanding the shape of a market’s response, identifying which segments are structurally your allies and which are structurally indifferent — it’s genuinely useful.
[SCREENSHOT 5: Report Agent output — the final analytical brief generated after simulation completes. Show the structured findings about audience segment behavior, key insights, and the conversational interface where you can ask follow-up questions.]
The Shift That Just Happened
The global market research industry exists because understanding how humans will behave at scale used to require scale to study. You needed large teams, long timelines, expensive methodologies.
The computing equivalent of a $500,000 consulting engagement is now accessible for the cost of a few API calls. The analysis that a team of 15 McKinsey analysts would take 10 weeks to produce can be approximated — with different tradeoffs — in an afternoon.
This doesn’t replace judgment. You still need to know what question to ask, how to interpret the output, and what to do with the findings. The analytical intelligence still has to come from somewhere.
But the infrastructure for simulation at scale? That just became a $100 decision instead of a $500,000 one.
MiroFish is early, imperfect, and running on a GitHub repo that a student shipped in 10 days. It’s also a preview of what market intelligence will look like in three years.
If you’re in marketing, now is a good time to get familiar with it before it becomes table stakes.
Great read thanks for sharing!
curious as to the quality of the responses (output). If I have 10 or 50 or 1000 or ALL agents (just asking an LLM) aren't we just converging towards the mean of all possible answers/responses and outcomes? Please explain the value here.